
It’s time to start reporting on my Chat implementation! Rather than reporting solely on Salesforce Chat though, I want to report on all work item routing via Omni-Channel. We route both cases and chats with Omni (so far). My goal in all of this is to build the coolest service dashboard ever that will show me how and when things are being routed and what happened to them in the end. I am picturing it being part real time and part trended analysis. Its going to be rad. But before I can even start building the dashboard… I need datasets! And to get datasets I need data and that means digesting these Omni-Channel objects in the Data Manager. Did you know there are 21 objects used in routing and what not? That’s pretty crazy! Thankfully, I’ve identified only 5 that we really need to show what I want to show (so far). So let’s do it!
Make Sure You Have Access
First, make sure that both you and the Analytics Cloud Integration User have access to the objects you need. You’ll want to make sure that you have read access on the objects and on all the fields you want to digest. Here are the objects I’m digesting:
- AgentWork
- ServiceChannel
- LiveChatTranscript
- UserServicePresence
- ServicePresenceStatus
If you are your Salesforce Admin, you already know how to do this. If you aren’t, then you should probably go talk to your Salesforce Admin. If you are the admin but are just getting started, check out this Trailhead Module on Data Security.
There were a few fields that I was not able to digest for whatever reason. These were things like IsAutoAcceptEnabled and ShouldSkipChannelCheck on the AgentWork object. I’m not concerned about it because I don’t want to report on those things anyway. If you run into any errors during Data Sync, just review which fields you decided to pull in and revise if necessary.
I probably don’t need to say it, but you should also make sure that you have at least one record created for all of these objects. That means you should have Presence Statuses created, at least one Service Channel, have routed work at least one time so that there is a Work Item, and have gone online in Omni-Channel so there is a Presence record recorded.
Connecting the Dots
I mentioned earlier that there are 21 objects used in Omni-Channel routing. That means there are lots of relationships, and that also means we have to reconnect all those relationships using record Id’s as our primary key in the dataflow. I’m doing all this in a dataflow because that’s where all the rest of my service data is connected and transformed already. Eventually, I will move it all to the new Data prep tool once there is a conversion tool available.
We’re going to end up with a few different datasets:
- Omni Agent Work
- Omni Chat Transcripts
- Omni User Presence
And I will likely end up with even more by the end of this, depending on my final list of requirements for the dashboard.
Omni Agent Work
This dataset is going to allow us to analyze things like:
- Agent Work by Service Channel
- How much work gets routed each day
- How the work is getting routed (in which queues)
- Average response times by agent or team
- Average active time by agent
- Average handle time by agent
- Work by routing type
- Declines by Agent and Reason
- Average agent capacity when declined
- and MORE!
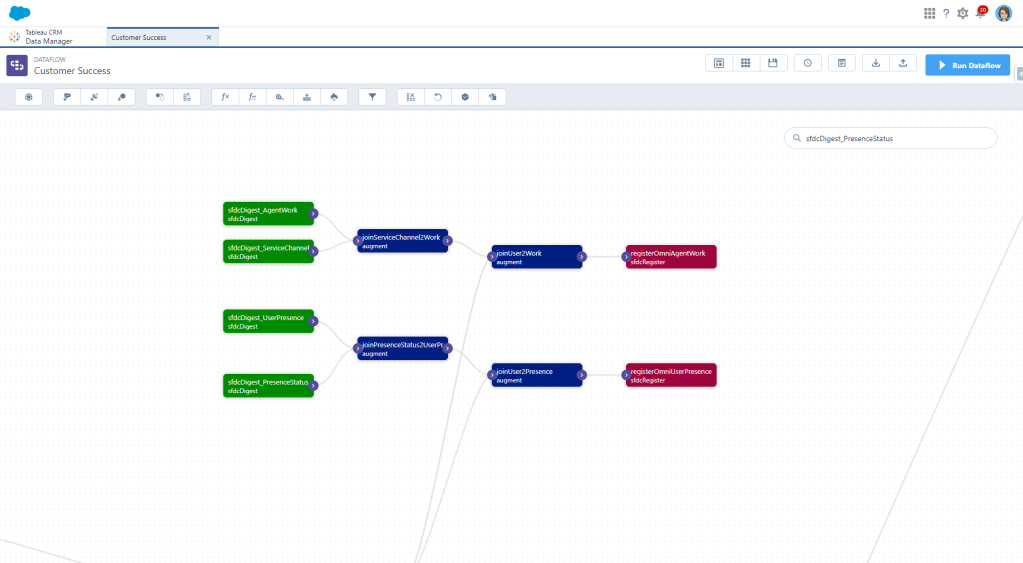
First we need to create a digest node for the AgentWork object. I’m pulling in most fields right now until I figure out what I actually need and what I don’t because I hate having to go back and grab another one and then wait for the dataflow to run again.
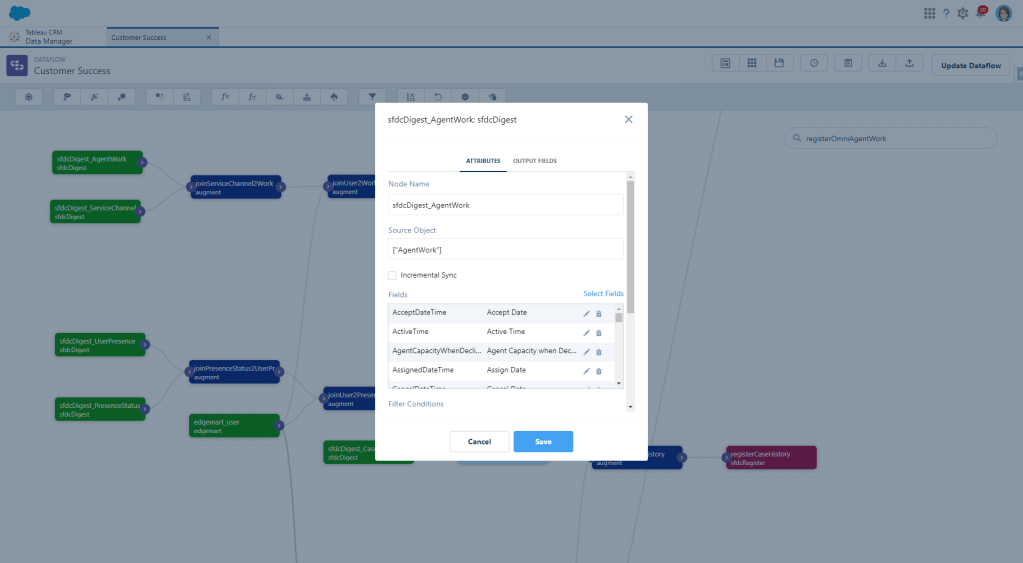
You’ll do this same thing for the ServiceChannel object. For Service Channel, I’m only grabbing the Id and the Master Label.

And now we want to join these together using an Augment node. Your left source will be AgentWork, using ServiceChannelId as your key. The right source will be ServiceChannel using the Id as the key.
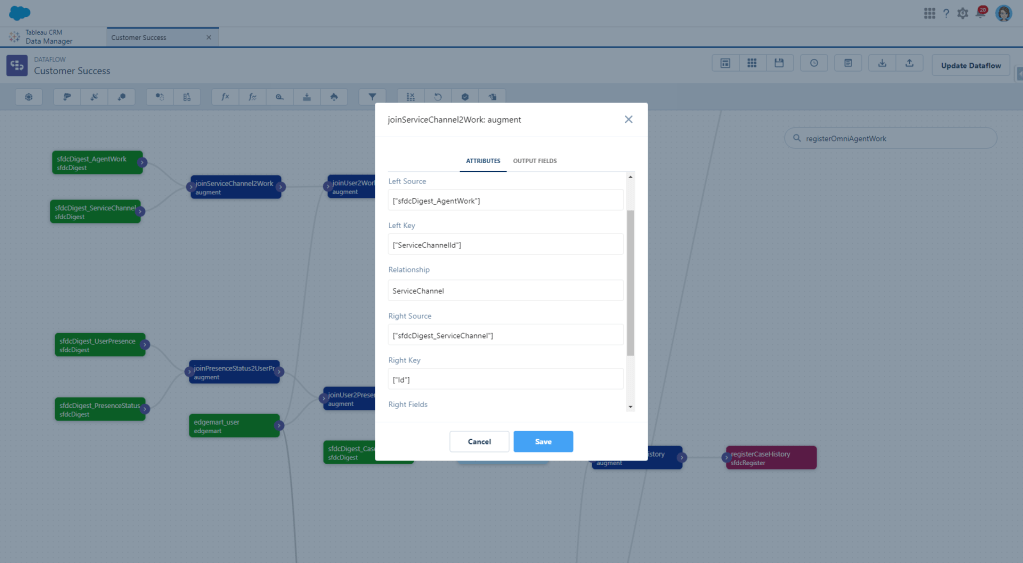
Since I have a lot of things on my list about agent productivity, I need to know who the agent actually is. As it stands, we only have a User Id, so now we need to augment User data too, using that UserId field as our key. Since I’m adding these nodes to an existing dataflow, I already have user data available. If that’s not the case for you, just do another digest of your User object.
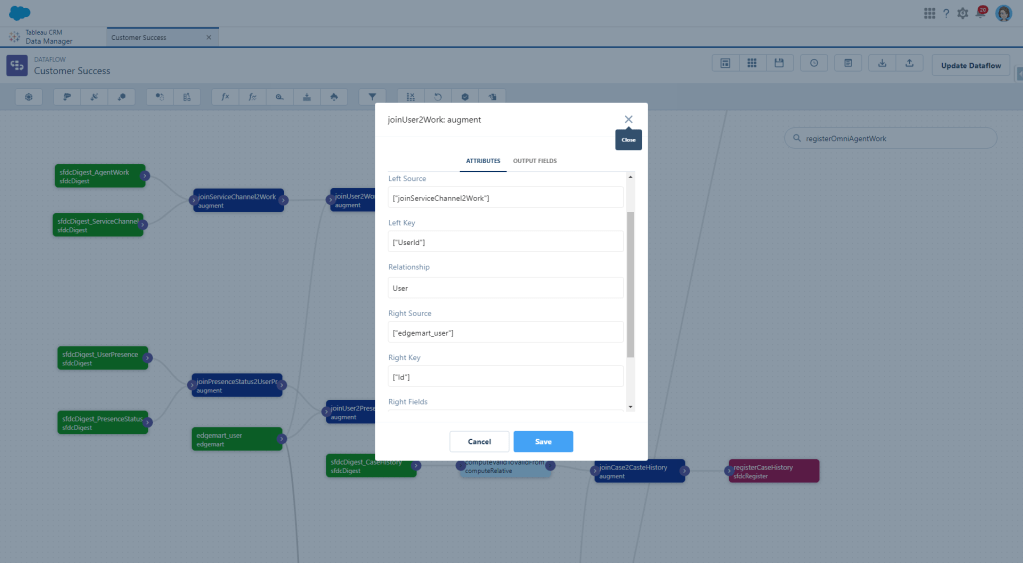
Then we’ll add a register node to output all this as our Omni Agent Work dataset, and BOOM. We’re done with this one!
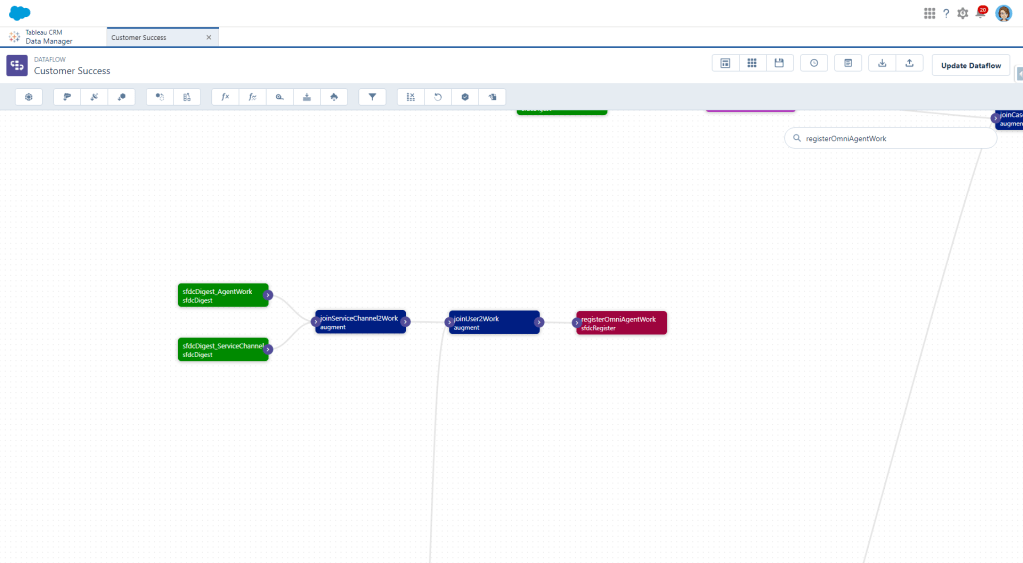
Omni Chat Transcripts
To get more information about my actual Chats, we want to look at the Chat Transcript. These records hold super valuable information like how many messages the agent sent vs the customer, time in between messages, browser info, the page the customer was on when they requested the chat, etc. Cool stuff! There are actually more Chat objects that I want to join later that will give us even cooler data, but I’m just not ready for them yet. Probably I’ll do another post just for the final chat data model. For now, I’m just going to be looking at the Chat Transcript, the customer who was chatting, and the agent who owns the chat.
We’ll start again with our Digest nodes. I’m only adding a Digest for the Chat Transcript because I already have a node for Contact, but add that in if you don’t have it already!
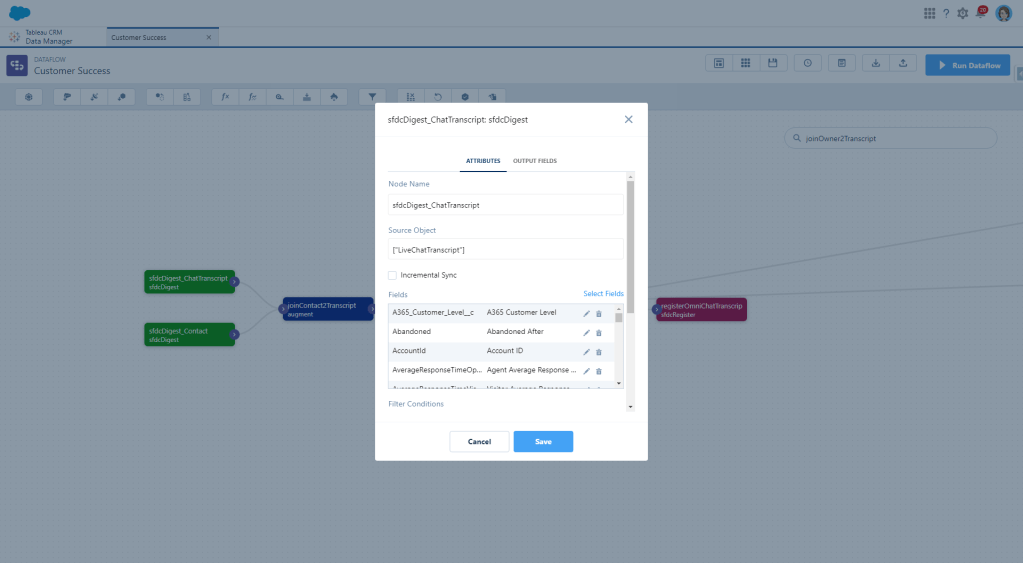
I only care about Contacts connected to the Chat Transcript right now, but the Chat Context gives you options for Contact, Lead, Case, and Account so there is a chance you would also want to augment those records depending on what reporting you are wanting to do. Next we’re going to add an Augement node so that we can join that Contact data.

And even though you can fill the AccountId on the Chat Transcript, I’m not, so I’m also going to Augment Account data based on the Contact’s AccountId that I just joined.
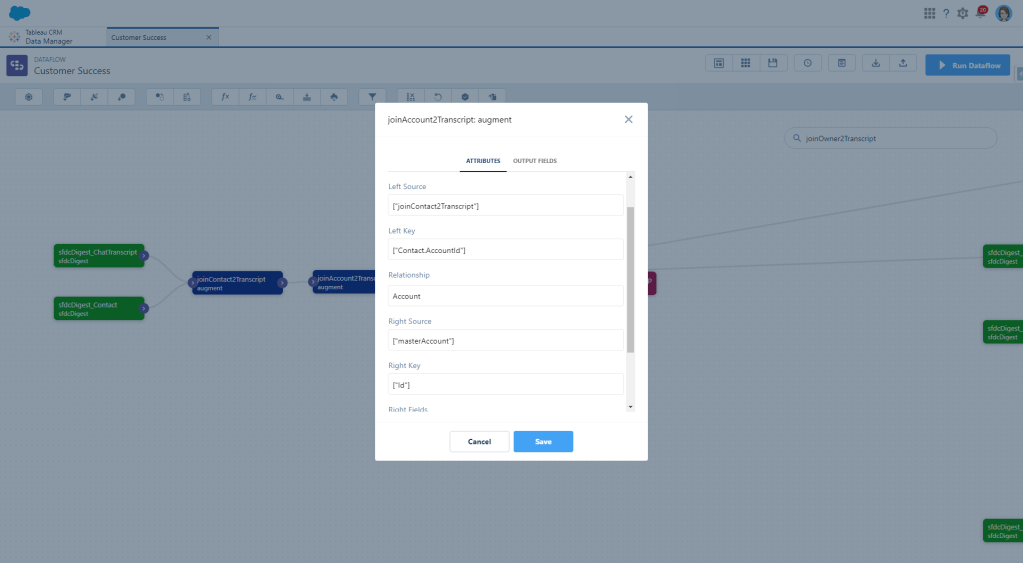
And now all I need to do is join my Agent data. Remember, since we are already using User data from the last dataset, best practice would be to reuse that node and not digest it again.

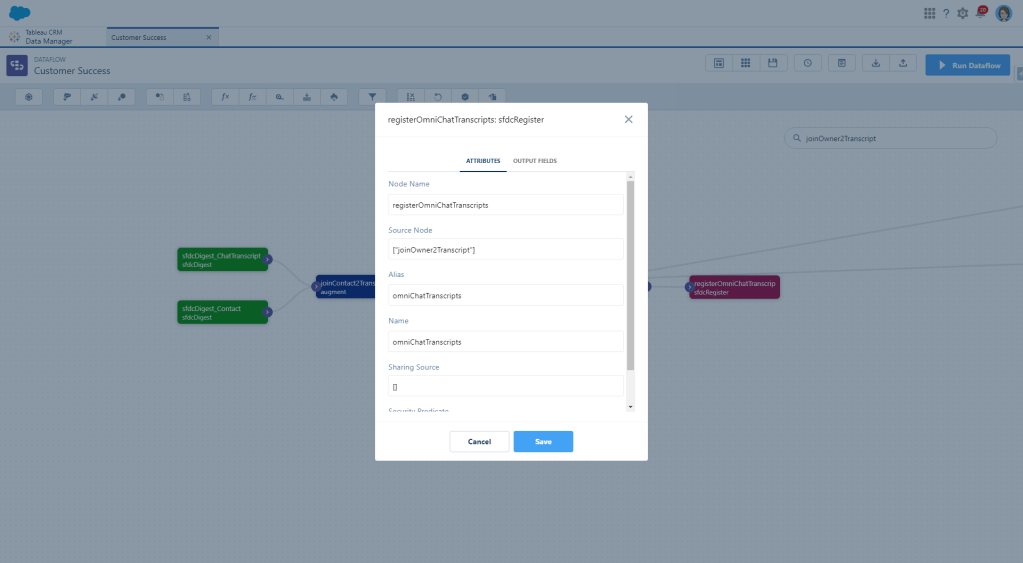
And now just add the Register node so that we can output this to a dataset!
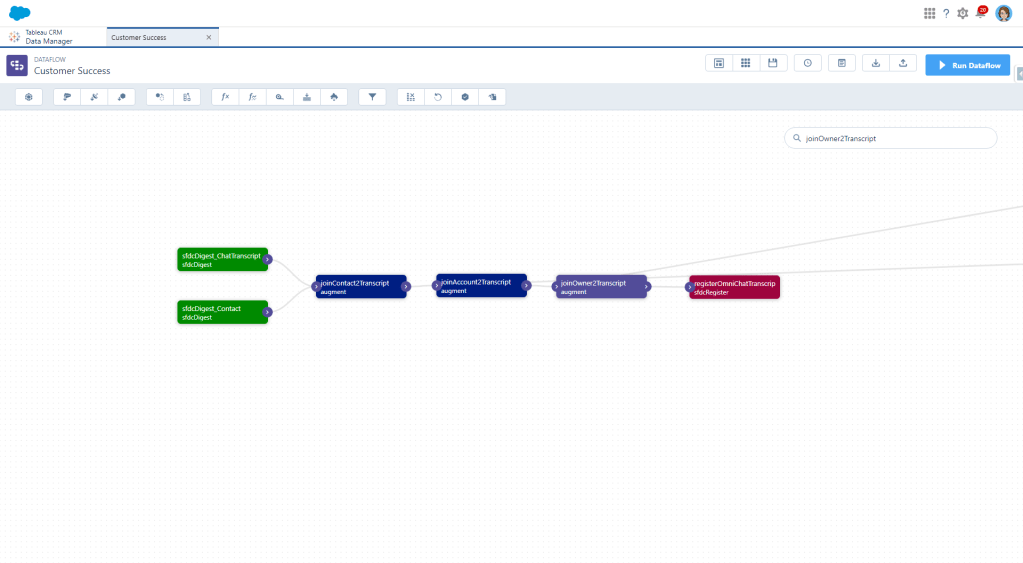
And our final product for this Omni Chat Transcripts dataset looks like this:
Omni User Presence
And for our last dataset in this data model (at least for now), we want to look at our User Presence records to see how often our agents were in each status. This will help us analyze if there are statuses that no one ever uses and we can get rid of them, or maybe we find a couple agents who are trying to stay in a Busy status all day instead of making themselves available for work.
We need to Digest two objects for this one. The first one will be UserServicePresence. I grabbed most fields from this because, again, I wasn’t sure yet what I would need when I start building.
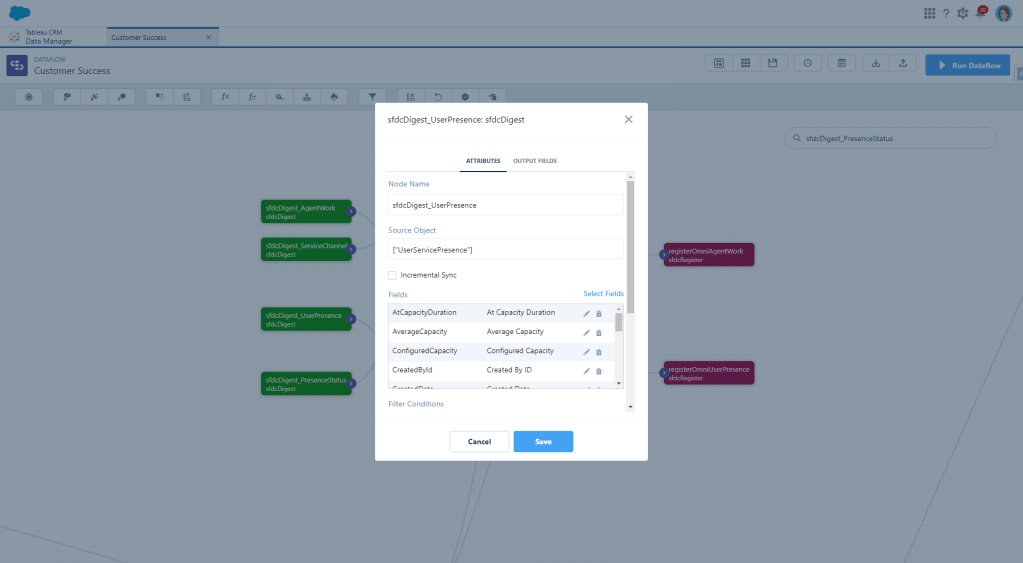
And then you’ll also want to Digest ServicePresenceStatus, which are your actual Presence Statuses. From here I just grabbed the Id and Master Label just like we did with the Service Channel.

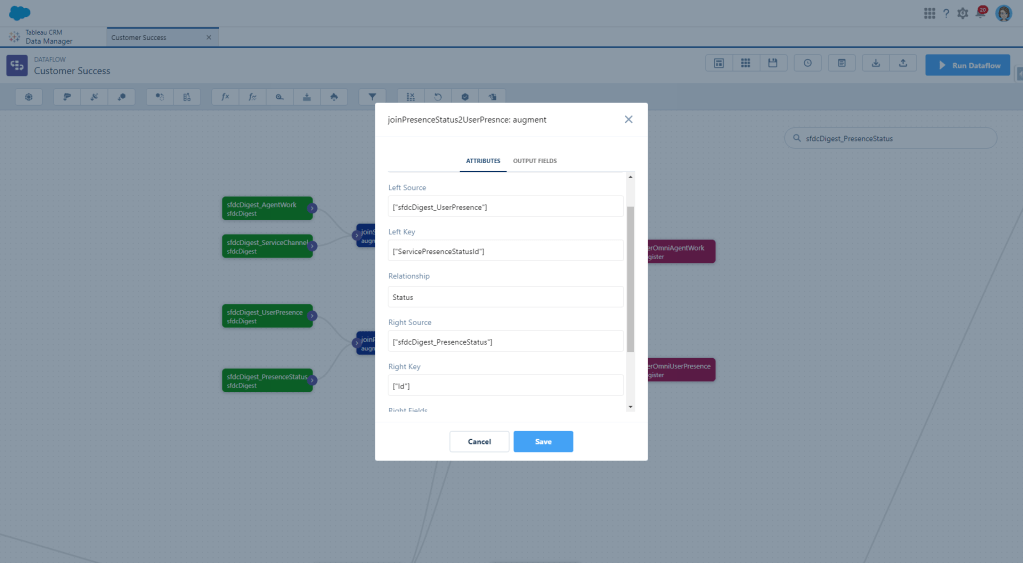
Now we’ll add an Augment to join the ServicePresenceStatus to the User Presence using ServicePresenceStatusId as the key.
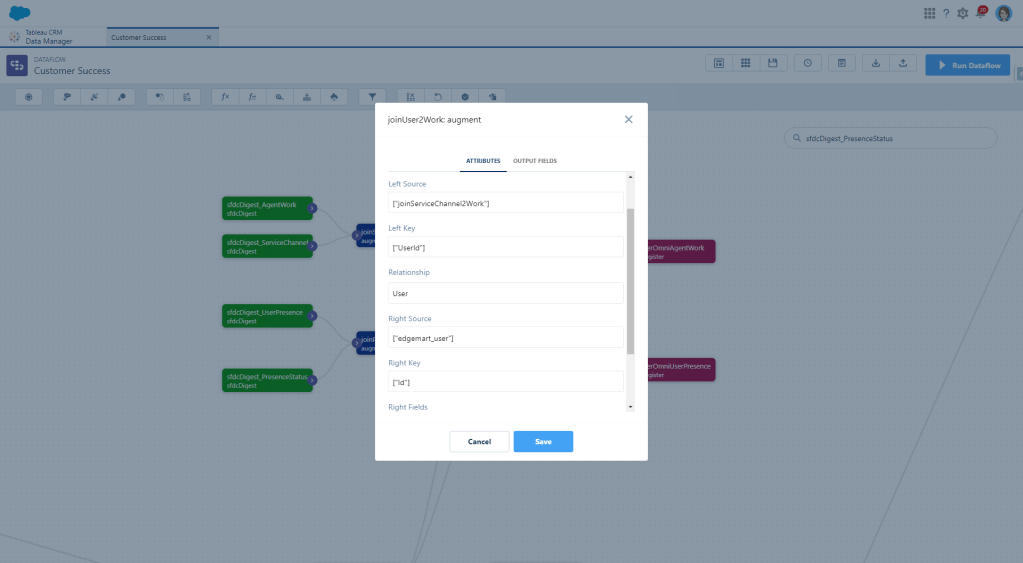
And because we want to be able to group this data by Agent and show cool insights, we need more than just a UserId. So let’s also Augment our User data again, using that same Digest node from the beginning.
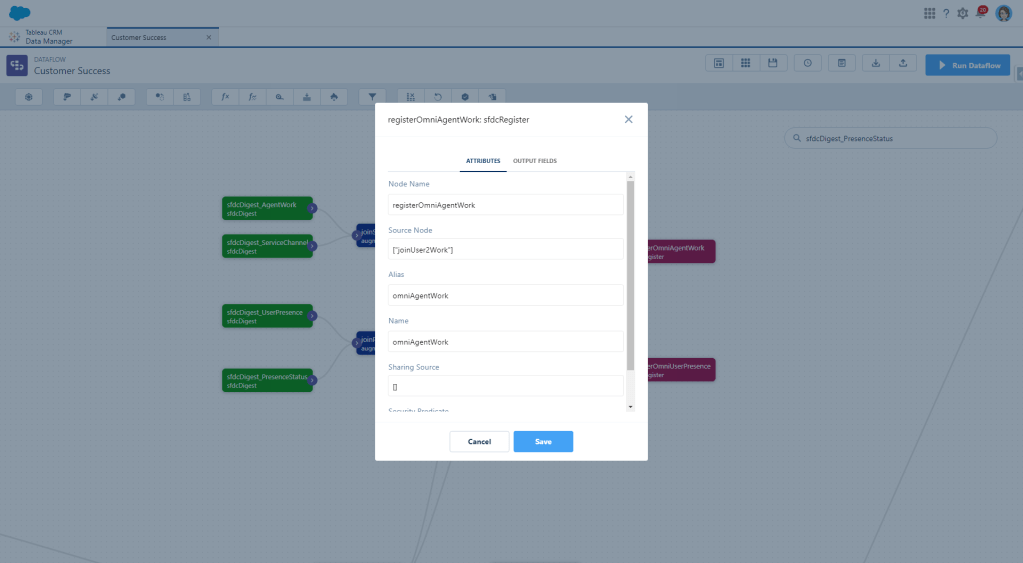
And with a Register node, we’re done!
Here’s our final Omni User Presence model:
Remember to save your work and if you want to start it now, go ahead and click Run Dataflow. When it’s done, we’ll have 3 new shiny datasets to use when we’re ready to start building!

Pingback: Extending Your Chat Reporting With Tableau CRM and Chat Transcript Events – Force For Fun